Generative AI Won the Headlines. Classical AI Still Runs the World.
I recently went back through nearly every project our engineers have built since 2018 — 181 projects across 100E, AIAP, SIP, AIAP for Industry and LADP (excluding our internal projects and special customer projects) — and mapped each one by the AI technique it used. I wanted to see, with evidence rather than impression, how our work had actually changed.
The headline trend is unmistakable. Generative AI went from zero percent of our portfolio in 2022 to effectively all of our most recent work in 2026. The obvious reading writes itself.
Generative AI has won. The future has arrived. Here is the proof.
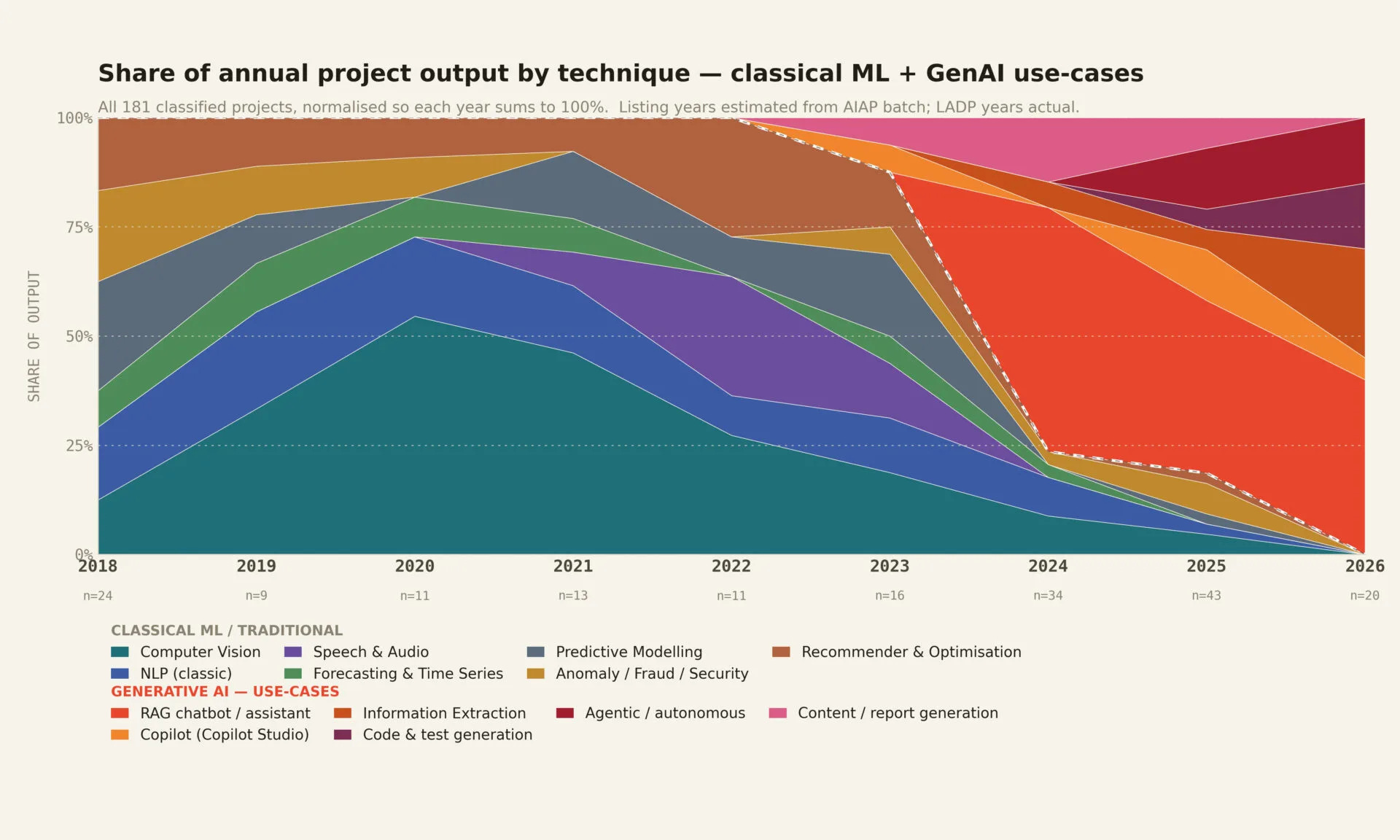
But a chart is only as good as the judgment you bring to it. And when I read this one carefully, it does not say what it appears to say. The fact is, it does not show where AI value lives. It shows what companies are asking us to build. Those are not the same thing — and the gap between them is the most important story in the data, one that most of Singapore is currently reading backwards.
The chart measures demand, not value
Our project portfolio is a mirror of what the market wants to build. And right now the market wants generative AI, because it has been told relentlessly that this is the only AI that matters.
This is not an accident. Three forces push in the same direction.
- The hype is at full volume.
- Generative AI is the lower-hanging fruit — you can stand up a chatbot in a fortnight with no labelled data and a demo that looks magical to a steering committee.
- And a magical demo is easy to fund.
So our portfolio tilted to one hundred percent generative. Not because generative AI is the right tool for one hundred percent of problems. Because it is the tool one hundred percent of clients are currently asking about.
The deeper point is not “use classical AI instead of generative AI.” It is that the entire classical-versus-generative debate is the wrong frame. Both are the same kind of thing. And once you see what kind of thing they are, the real divide comes into focus.
All AI is prediction. The moat is judgment.
Strip away the marketing and every AI system — the vision model on the factory line, the fraud detector in the bank, the large language model writing your email — does one thing. It performs prediction. Pattern recognition at enormous scale, in microseconds, at a cost of cents.
What no AI does, what it structurally cannot do, is supply judgment. The weighing of trade-offs. The reading of context. The decision about what is worth building in the first place. The ownership of the outcome when it goes wrong.
Chalmers and colleagues, in their 2026 work on the acceleration of artificial intelligence, give this a useful structure. They decompose professional work into three parts:
- production – the mechanical making of things;
- judgment – the deciding; and
- coordination – the glue between people and systems.
Production is what gets automates. Judgment is what does not. And their sharpest observation is what they call judgment density: as the cost of production collapses toward zero, the number of judgment calls per hour of work goes up, not down. A developer who once spent most of the day typing code now spends most of the day deciding what to build and verifying what the machine produced. AI made production cheaper. It did not make judgment easier.
Think of the spreadsheet. It eliminated arithmetic. It did not eliminate accountants — it made their judgment more valuable, because the grunt work that used to fill their day was gone and what remained was the part that required a human. Generative AI is the spreadsheet moment for knowledge work. The arithmetic is now free. The accountant is the moat.
Prediction has become abundant and cheap. Judgment has become scarce and expensive. Value flows to what is scarce. That single sentence is the deepest thing our data is telling us, and it is the opposite of “buy more GenAI.”
Why the mirage is so convincing
If judgment is what matters, why does generative AI seduce so completely?
Arvind Narayanan of Princeton has the cleanest explanation I have found: the gap between capability and reliability. What an AI can do in its best case is capability. How consistently it performs across all cases is reliability. Every AI demonstration shows you capability. Every AI deployment tests reliability. The space between the two is exactly where judgment is required — and it is where most organisations fall in.
Generative AI is the most spectacular capability demonstration ever built. That is precisely why it is the lower-hanging fruit. The fruit hangs low because the demo is easy, not because the deployment is. When Air Canada’s chatbot confidently invented a refund policy that did not exist, the system was perfectly capable of generating plausible text. It was not reliable. The airline was held liable for the gap. The capability was never the problem. The reliability was, and reliability is a judgment problem, not a model problem.
Why most AI bets are failing
This is also why the returns are not showing up. MIT’s NANDA study in 2025 found that roughly ninety-five percent of corporate generative AI pilots delivered no measurable impact on the bottom line. The number went viral as evidence of a bubble. I read it differently.
The explanation sits right inside the production-judgment distinction. Organisations are investing in production capacity — buying tools, generating more output — without scaling their judgment and verification capacity to match.
They produce more, of lower quality, and the return never materialises. More output is not more value. Better judgment is more value.
A company that buys generative AI to make more of everything, without investing in the humans who decide what is worth making and whether the output is correct, has bought a faster way to produce work that nobody can stand behind.
What actually runs the real world
Now walk onto a factory floor, into a bank’s fraud operations, into a port or a power grid or a hospital’s diagnostic pipeline.
What is running there is not a large language model. It is a vision model inspecting welds. A forecasting model predicting demand and failure. An anomaly detector catching fraud in milliseconds. An optimisation engine routing trucks and scheduling cranes. These systems move money, goods and risk at industrial scale, quietly and reliably, almost entirely without generative AI.
Based on our experience across finance, healthcare, manufacturing and logistics, my estimate is that classical, discriminative machine learning still powers something on the order of seventy to eighty percent of the AI that creates real industrial value today. Not the AI that gets written about. The AI that gets used.
And the reason is the same gap as before, read the other way: these systems crossed from capability to reliability years ago, embedded in production with human judgment built around them. They do not demonstrate well. They simply work. That is the whole point.
The agentic frontier, honestly
The next wave is agents, and our own newest work is already chasing it. In our LLM application development programme (LADP), the earliest cohorts built retrieval chatbots almost exclusively. The most recent ones are turning to agents and code generation.
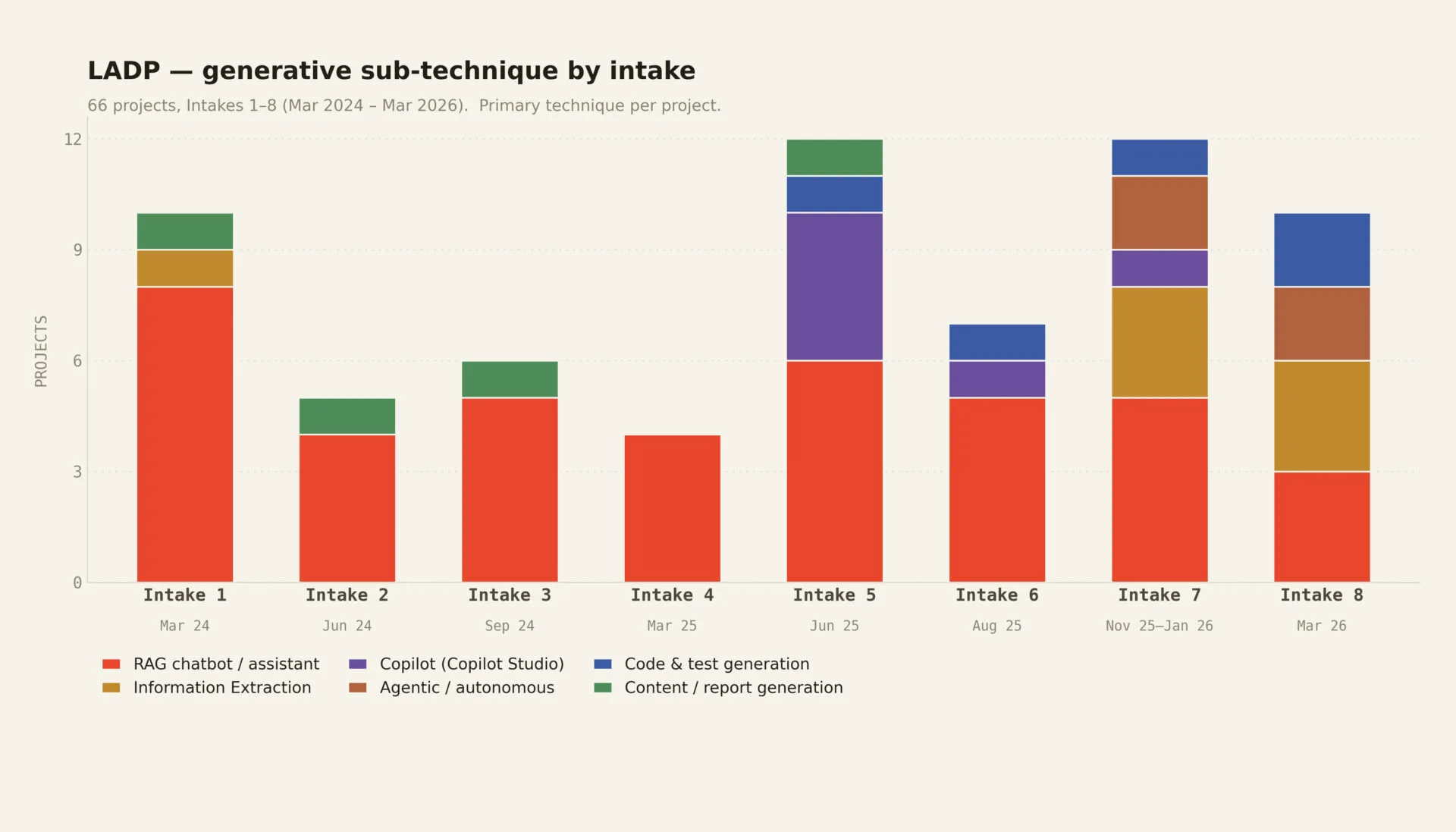
And here I want to be careful, because this is where the hype is loudest and the evidence is most sobering. The Scale AI and CAIS Remote Labor Index, published in October 2025, measured how much real freelance work the best AI agents can actually complete. The answer was about two and a half percent. That leaves ninety-seven and a half percent of real work still requiring human judgment.
Narayanan and his colleagues frame the structural reason as a trilemma. You cannot simultaneously have an agent that is:
- general-purpose
- operating in high-stakes domains, and
- fully automated with no human in the loop.
You may pick any two.
A general-purpose agent in a high-stakes domain must keep a human in the loop. A fully automated high-stakes agent must be narrow. The implication is permanent, not transitional: human judgment is a design requirement of any serious system, not an inconvenience we will engineer away next year.
The question Singapore should be asking
There is a way to see how the major players approach all of this.
The United States asks, “How powerful can we make AI?”
China asks, “How can we use AI today?”
Both are reasonable strategies for their scale. Neither is available to us.
Singapore’s question is the third one: “How do we build the judgment to deploy whatever emerges?”
We cannot win the capability race or the scale race. We can win the judgment race. And we have evidence that this is not wishful thinking. Across more than 300 projects, our deployment rate into production sits near fifty-three percent, against an industry average below ten percent.
That gap is not a modelling advantage. It is judgment, deployed.
It is what happens when you put domain experts and trained engineers around the prediction, instead of expecting the prediction to carry itself. This is why we grow our own timber.
The nine months of our AI Apprenticeship Programme (AIAP) are not about teaching people to use AI tools — the tools change every quarter. They are about building the judgment, the reliability instinct, and the contextual knowledge that no model possesses and no bootcamp can shortcut.
Judgment cannot be boot-camped.
What to hold onto
I am not arguing against generative AI. It is extraordinary for language, for knowledge retrieval, and increasingly for agentic automation, and we are building exactly those systems with conviction. I am arguing against generative AI for everything — against mistaking a stampede toward cheap prediction for a strategy.
Three things, then.
Start with the problem, never the technology. A company that decides it will “do GenAI” has already made the classic mistake: it picked the answer before it understood the question.
Respect the workhorses. If your problem is prediction, detection or optimisation, classical machine learning is very probably still your best tool. The fact that it is no longer fashionable is your advantage, because your competitors are too distracted to build it well.
And invest in the scarce thing – human judgement. Prediction is now a commodity you can buy by the cent. Judgment is not. The organisations that win the next decade will not be the ones that generated the most. They will be the ones that built the human judgment to decide what was worth generating, and to stand behind it when it mattered.
The toolbox will keep changing. It always has. The discipline does not. Match the right tool to a real problem — and never confuse the abundance of prediction with the scarcity of judgment.
That was always the job. The mirage just makes it harder to see.